深度解读KubeEdge架构设计与边缘AI实践探索
摘要:解读业界首个云原生边缘计算框架KubeEdge的架构设计,如何实现边云协同AI,将AI能力无缝下沉至边缘,让AI赋能边侧各行各业,构建智能、高效、自治的边缘计算新时代,共同探索智能边缘的新篇章。
本文分享自华为云社区《DTSE Tech Talk | 第63期:KubeEdge架构设计与边缘AI实践探索》,作者:华为云社区精选。
本期直播的主题是《边云协同新场景,KubeEdge架构设计与边缘AI实践探索》,华为云云原生DTSE技术布道师Elias,与开发者们交流了云原生边缘计算领域的理论与技术研究,跟大家分享了云原生边缘计算平台KubeEdge的核心架构、基于KubeEdge的边缘AI实现以及多行业、多场景下的实践经验与优秀案例,展望了云原生边缘计算的未来。
云原生边缘计算的行业背景与挑战
随着云原生技术的发展,云原生正在从数据中心向边缘延伸,云原生边缘计算技术应运而生。云原生边缘计算是一种新型的边缘计算架构,将云计算的弹性和可扩展性与边缘计算的低延迟和数据处理能力相结合,基于Kubernetes、Docker等云原生技术,将计算、存储、网络等资源部署在靠近数据源的边缘节点上,实现数据的实时处理和分析,在物联网、智能制造、智慧医疗等领域有着广阔的应用前景。
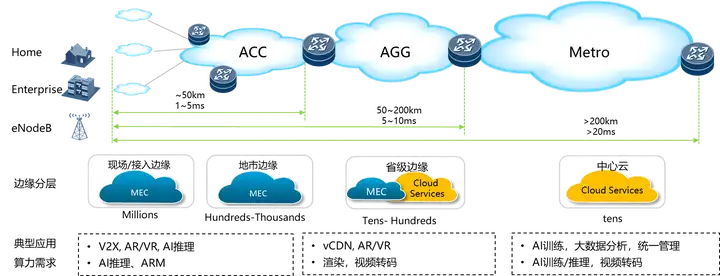
云原生边缘计算能带来更高效、更稳定的资源调度与管理,拥有丰富的技术生态集成,带来经济利益的提升。但由于边缘计算细分领域众多、互操作性差,边云通信网络质量低、时延高,云原生边缘计算仍存在很多技术难题与挑战。
云原生边缘计算平台KubeEdge架构解析
KubeEdge(https://github.com/kubeedge/kubeedge)是CNCF首个云原生边缘计算项目,也是业界首个云原生边缘计算框架。KubeEdge不断在边缘计算领域进行技术探索,例如面向边缘AI的场景实现了业界首个分布式AI协同框架子项目Sedna;面向边缘容器网络通信领域实现Edgemesh;面向边缘设备管理领域发布了云原生边缘设备管理接口DMI,支持边缘设备以云原生的方式接入集群。除在技术方面不断探索外,KubeEdge还积极与友商和高校等研究机构合作推动云原生边缘计算的案例落地,例如全国高速公路取消省界收费站、智能汽车等项目。
KubeEdge架构图如下图所示。
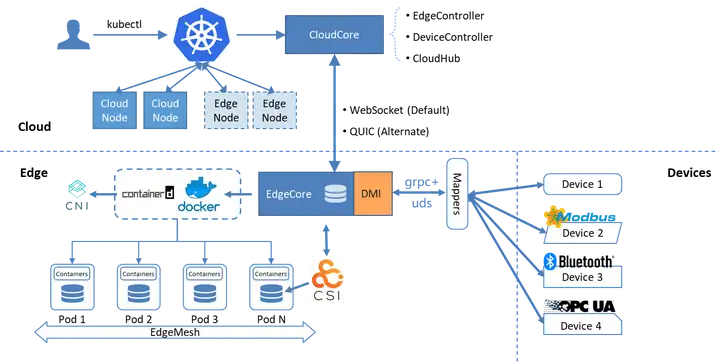
KubeEdge核心的设计理念是凭借Kubernetes中的云原生管理能力,在边缘计算的场景对原有Kubernetes做了功能增强,主要包含以下三点:
- 云边消息可靠性的增强。云端向边端发送控制命令时会检测边缘是否回传ACK应答,确保消息下发成功;另一方面,云端会对控制命令编号,记录消息的下发,避免重发消息可能导致的带宽冲击问题。
- 组件的轻量化。为了应对边缘场景资源受限的问题,KubeEdge在edgecore中集成了一个经过裁剪后轻量级的kubelet,用以管理边缘应用的容器,目前KubeEdge自身组件占用已经能够减少至70M左右。
- 边缘物理设备管理。KubeEdge利用设备管理插件Mapper以云原生化的方式纳管边缘设备。用户能够定义设备配置文件,以Kubernetes自定义资源的方式云原生化管理边缘物理设备。
KubeEdge核心技术介绍
本次直播主要介绍了KubeEdge边缘设备管理与边缘容器网络这两个关键技术。
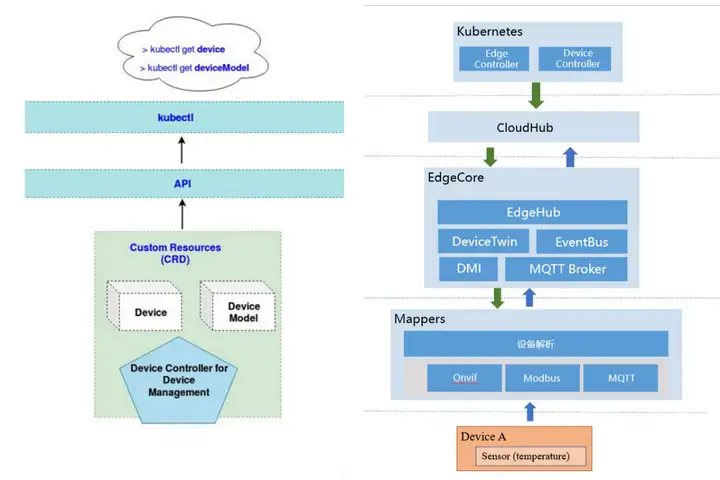
KubeEdge使用云原生的方式管理边缘设备,实现了基于物模型的设备管理API,表现为DeviceModel与DeviceInstance这两个Kubernetes CRD:
- DeviceModel是同类设备通用抽象。同一类同一批次的设备中一些设备属性往往是相同的,能够抽象为DeviceModel进行管理。
- DeviceInstance是设备实例的抽象。一个DeviceInstance就对应一个实际边缘设备,定义了设备协议、设备访问方式等内容。
KubeEdge使用Mapper设备管理插件实际管理边缘设备。Mapper中集成了设备驱动,能够与设备通信、采集设备数据与状态。Mapper通过实现KubeEdge edgecore中的DMI设备管理统一接口完成自身向KubeEdge集群注册、设备数据上报的能力。
KubeEdge中已经内置了例如Modbus、Onvif等典型协议的Mapper,也提供Mapper开发框架Mapper-Framework,便于开发者自行开发其他Mapper。Mapper-Framework内置了DMI API以及数据面、管理面的能力,能够自动生成Mapper工程的模板,用户只需实现设备驱动层能力即可实现全量Mapper能力。
在边缘场景下,边云、边边网络割裂,微服务之间无法跨子网直接通信;而且边缘侧网络质量不稳定,节点离线、网络抖动是常态,且边缘节点常位于私有网络,难以实现双向通信。为应对边缘容器网络通信存在的问题,KubeEdge构建了数据面组件Edgemesh,为应用程序提供了服务发现与流量代理功能,同时屏蔽了边缘场景下复杂的网络结构。
Edgemesh的功能特点如下:
- 采用P2P打洞技术。Edgemesh通过P2P打洞技术打通边缘节点间的网络,让边缘节点在局域网内或跨局域网的情况下都能通信。
- 内部DNS服务器。Edgemesh内部实现轻量级的 DNS 服务器,让域名请求在节点内闭环。这一特性主要针对边云连接不稳定的情况,目的是在边缘节点与云节点断开连接后也能正常完成域名解析。
- 轻量级部署。Edgemesh仅以一个Agent的方式部署在节点上,能够节省边缘资源。
Edgemesh的结构如下图所示:
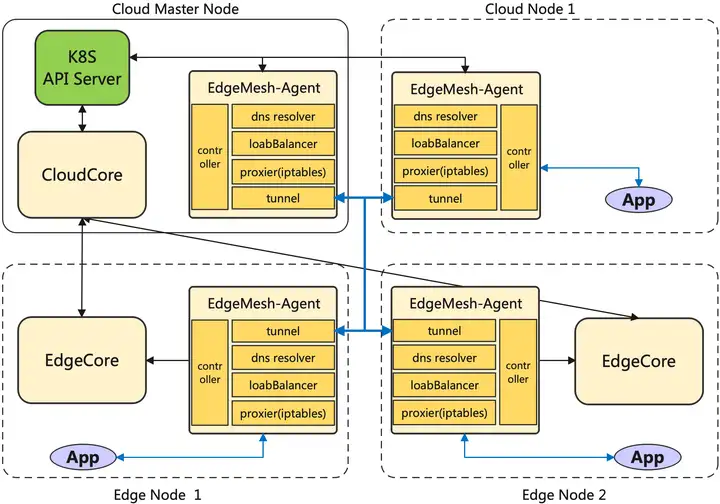
Edgemesh结构主要包括五个部分:
- Proxier: 负责配置内核的 iptables 规则,将请求拦截到 Edgemesh 进程内
- DNS: 内置的 DNS 解析器,将节点内的域名请求解析成一个服务的集群 IP
- LoadBalancer: 集群内流量负载均衡
- Controller: 通过 KubeEdge 的边缘侧 Local APIServer 能力获取 Services、Endpoints、Pods 等元数据
- Tunnel:利用中继和打洞技术来提供跨子网通讯的能力
基于KubeEdge的边缘AI实现
随着人工智能技术的发展,将AI能力下沉边缘侧也是目前重要的研究方向,边缘AI指在边缘计算环境中实现的人工智能,允许在生成数据的边缘设备附近进行计算,具有实时性、隐私性、降低功耗和带宽的优势,本次直播也介绍了基于KubeEdge的边缘AI实现。
KubeEdge面向边缘AI场景提出边缘智能框架Sedna,是业界首个分布式协同AI开源项目,基于KubeEdge提供的边云协同能力,支持现有AI类应用无缝下沉到边缘,能够降低构建与部署成本、提升模型性能、保护数据隐私。Sedna拥有以下特点:
- 提供AI边云协同框架。Sedna为用户提供了跨边云的数据集和模型管理能力,帮助开发者快速构建自己的AI应用。
- 支持多种边云协同训练和推理模式。当前Sedna拥有协同推理、增量学习、联邦学习与终身学习四大范式,分别针对边侧资源受限、模型更新、原始数据不出边缘和小样本与边缘数据异构问题做了改进优化。
- 具有开放生态。Sedna支持业界主流AI框架例如TensorFlow, Pytorch, Paddle, Mindspore等,还提供开发者扩展接口,能够支持快速集成第三方算法。
Sedna也可以理解为云原生的边云协同框架,兼容Kubernetes KubeEdge云原生生态,架构图如图所示:
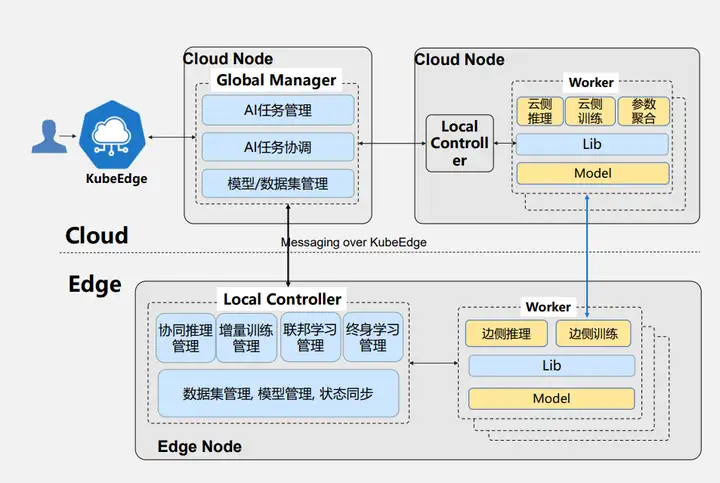
Sedna的架构主要包含以下四个部分:
- Global Manager: 是拓展的Kubernetes的CRD资源,实现的功能主要有AI任务的生命周期管理,比如创建、删除等
- Local Controller: 辅助云侧做一些边缘化的自治,并且完成本地模型数据集的管理控制
- Worker: 计算任务和推理任务的对象,对应于Kubernetes表现为部署创建的容器,用来实际进行训练推理
- Lib库: 能够将用户已有的AI应用改造成边云协同的方式
KubeEdge典型案例解读
KubeEdge目前已广泛应用于智能交通、智慧园区、工业制造、金融、航天、物流、能源、智能 CDN 等行业,本期直播选取多个典型案例进行了解读,包括基于KubeEdge的多云原生机器人编排、大规模CDN节点管理平台、基于KubeEdge/Sedna的楼宇热舒适度预测控制、基于KubeEdge的智慧园区等。
1、基于KubeEdge的多云原生机器人编排
目前机器人处于智能化的初级阶段,只能完成特定的一项或几项任务,不具备理解复杂指令和自主探索解决方案的能力。随着大语言模型的发展,我们希望借助大模型的能力助力机器人复杂指令的拆解,实现具身智能。
基于KubeEdge的多云原生机器人编排系统架构如图所示,主要分为云端大脑、边侧小脑、端侧机器人躯干。云端大脑部署大语言模型,能够按照用户指令自动生成机器人的控制代码并下发边侧小脑;边侧小脑具有机器人的一些基本技能,例如3D环境感知、路径规划、实时定位与导航,能够控制机器人完成移动、抓取;端侧机器人躯干具有众多传感器,能够向云端大脑、边侧小脑反馈状态,更新系统。
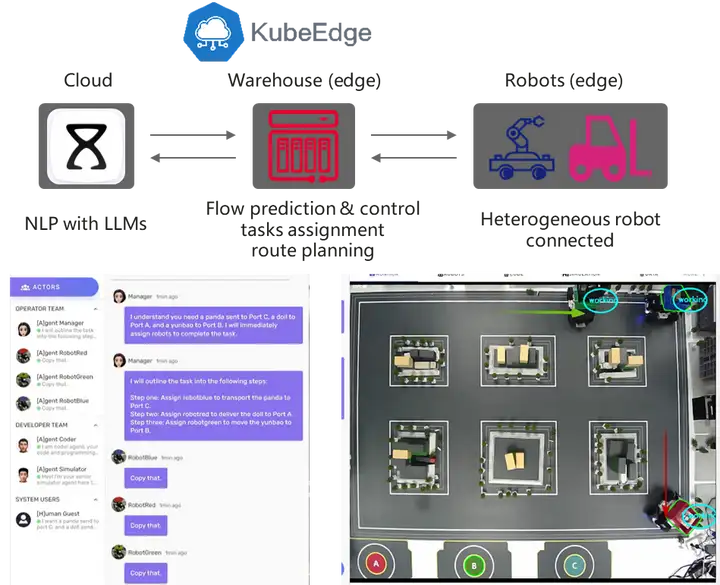
当前基于KubeEdge的多云原生机器人编排实现了基于多机器人协调的NLP驱动的任务理解和任务执行功能,能将云边端系统端到端部署周期缩短30%,机器人效率提高 25%,新型机器人集成周期由数月缩短至数天。
2、基于KubeEdge的大规模CDN节点管理平台
CDN节点指距离最终用户接入具有较少中间环节的网络节点,具有较好的响应能力和连接速度。CDN节点中往往存储了网站和应用程序的静态内容,能够提高访问速度;同时,CDN节点在物理布局上通常具有离散分布的特点,且网络连接可能不稳定。
基于KubeEdge的大规模CDN节点管理平台架构如下图所示。需要在各区域中心及数据中心建若干个Kubernetes集群,这些中心具有全量Kubernetes能力,包括负载均衡、网络插件相关能力,能够满足业务部署在中心云的需求,例如区域的日志汇聚、监控汇聚、镜像分发加速的能力,除了传统Kubernetes组件,在区域中心还部署了KubeEdge的云侧管理面组件cloudcore,通过cloudcore纳管边缘的CDN节点,边缘CDN节点全部以edgecore的形式,就近接入区域云端。
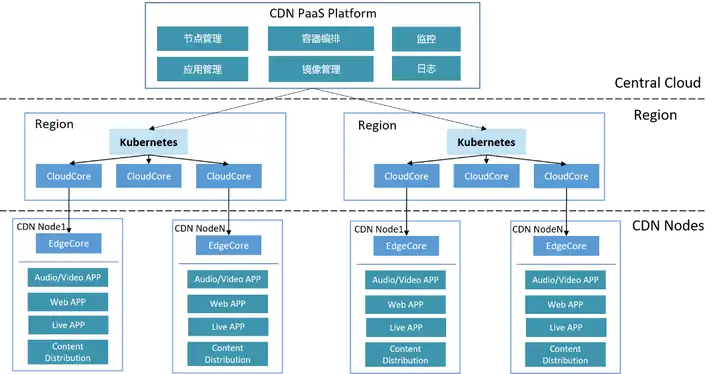
基于KubeEdge实现的大规模CDN节点管理平台具有边缘自治、智能化调度等多种优势,在边缘节点断连后容器无需重建,服务不中断,并且能提供节点间亲和性调度以及应用间亲和性调度,已经成功管理1W+边缘CDN节点,助力直播加速、视频点播加速。
3、基于KubeEdge/Sedna的楼宇热舒适度预测控制
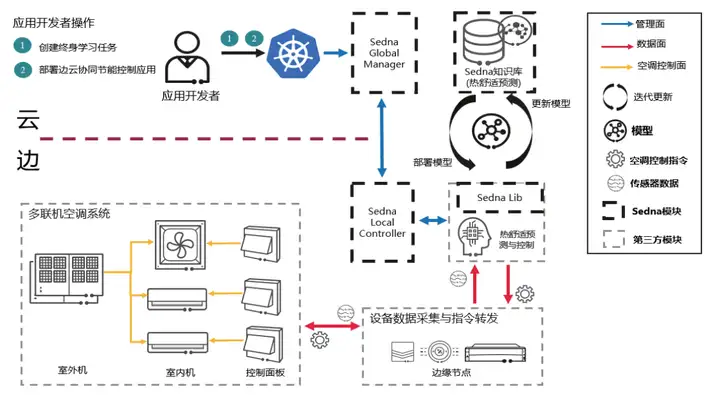
智能楼宇是智慧城市的重要组成部分,智能楼宇的自控系统通常位于边缘。热舒适度被定义为楼宇中的人对环境冷热的满意程度,这是一种定量的评估指标,能够把室内冷热环境参数的物理设定与人的主观评估联系起。准确的热舒适度预测结果能够帮助管理人员探索舒适度最佳的楼宇温度调整策略。但由于人员个体差异、房间与城市差异,楼宇热舒适度预测具有突出的数据异构与小样本问题。
基于Sedna的边云协同终身学习的热舒适预测控制具有云边协同和终身学习预测这两个优势,设计图如下图所示。云侧Sedna知识库会利用多地点多人员的历史数据集进行初始化,向边侧应用提供推理更新接口,实现云边协同推理;对于推理任务的复杂性,我们采用终身学习的机制,边端推理时面向已知任务直接推理,未知任务则联合知识库推理,并会对未知任务机进行学习,更新知识库。实验表明,热舒适度预测在KotaKinabalu数据集中预测率相对提升24.04%,能够为楼宇的温度调整策略提供依据。
更多KubeEdge应用案例,可访问直播回放链接回顾:https://bbs.huaweicloud.com/live/DTT_live/202407241630.html
作为业界首个云原生边缘计算社区,KubeEdge社区生态蓬勃发展,社区已吸引来自全球80+贡献组织的1600+贡献者, GitHub Star 超过7.5 k。KubeEdge最新版v1.18.0现已发布,新版本中,路由器管理器支持高可用性(HA)、增强CloudCore Websocket API 的授权,支持设备状态上报,Keadm 工具增强功能, 增强封装Token、CA、证书操作功能,欢迎前往社区下载体验https://github.com/kubeedge/kubeedge/releases/tag/v1.18.0
KubeEdge网站: https://kubeedge.io
GitHub地址: https://github.com/kubeedge/kubeedge
Slack地址 : https://kubeedge.io/docs/community/slack
每周三下午四点社区例会 : https://zoom.us/j/4167237304










